Table of Contents [expand]
Last updated March 24, 2025
The term dyno formation refers to the layout of your app’s dynos at a given time. The dynos in your formation do the app’s regular business like handling web requests and processing background jobs as it runs.
You can check your current formation at any time in your app’s Resources tab in the Heroku Dashboard, the heroku ps CLI command, or the Formation List API endpoint.
The Procfile and Your Dyno Formation
The default formation for simple apps is a web process type running on a single dyno. Demanding applications can consist of web, worker, clock and other process types as declared in your Procfile.
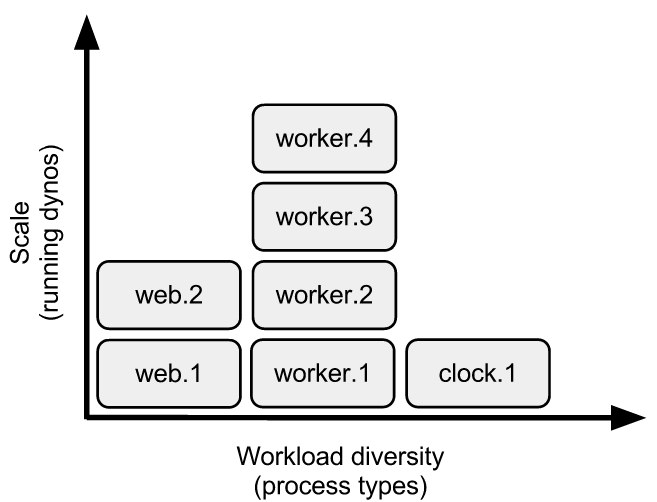
While the Procfile doesn’t determine the number of dynos to run per process, it’s a required file if you want to run any other process type besides web. Heroku starts one web dyno automatically, but other process types don’t start by default. You can scale your dynos for each process type separately.
When a web or worker dyno starts, the dyno formation of your app changes to reflect the number of running dynos of each process type. Subject to the dyno lifecycle, the dyno manager continues to maintain that dyno formation until you change it.
One-off dynos aren’t declared in your Procfile. They’re only expected to run a short-lived command, and then exit. They’re neither a part of your formation, nor affect it in any way.
Dyno Formation Changes
You can scale your dynos horizontally or vertically by changing the size or number of dynos. See Scaling Your Dyno Formation for more info.
We log all changes to your dyno formation:
$ heroku logs | grep Scale
2024-05-30T22:19:43+00:00 heroku[api]: Scale to web=2, worker=1 by abc@example.com
The logged message includes the full dyno formation, not just dynos you scaled.
Adding Redundancy to Your Formation
We recommend running at least two web dynos in your formation for important apps. Applications that run multiple running dynos are more redundant against failure. If some dynos fail, the application can continue to process requests while we replace the missing dynos. Typically, failed dynos restart promptly, but in the case of a catastrophic failure, it can take more time. Multiple dynos are also more likely to run on different physical infrastructure, for example, separate AWS availability zones, further increasing redundancy. If you have critical non-web process types, we recommend adding redundancy for those processes as well.